Project
Introduction
This project implements a complete kinematic control system for an anthropomorphic (human-like) 3-DOF robotic arm that mimics the structure of a human arm with shoulder, elbow, and wrist joints. The system employs analytical inverse kinematics derived from Denavit-Hartenberg parameters to compute joint angles that achieve desired end-effector positions in 3D space. Unlike numerical approaches, the closed-form solution enables real-time control with sub-millisecond computation times, making it suitable for dynamic trajectory tracking applications. The implementation handles multiple inverse kinematic solutions through elbow-up/elbow-down configurations, allowing the robot to navigate around obstacles while maintaining smooth motion. Integrated with ROS Noetic, the system demonstrates precise elliptical and circular trajectory following with ±1.5cm accuracy, validating the theoretical kinematic models through practical robotic control.
Objectives
-
To derive and implement analytical inverse kinematics for a 3-DOF anthropomorphic manipulator using DH parameters
-
To develop closed-form solutions handling multiple arm configurations (elbow-up/elbow-down) for obstacle avoidance
-
To achieve real-time trajectory tracking with sub-millisecond IK computation for dynamic motion control
-
To implement workspace validation ensuring all commanded positions are within the robot's reachable volume
-
To create smooth elliptical and circular path generators with adaptive height variations
-
To integrate the kinematic solver with ROS control infrastructure for hardware-agnostic implementation
Tools and Technologies
-
Framework: ROS Noetic with catkin build system
-
Programming Language: Python 3
-
Kinematics: Denavit-Hartenberg parameters, SymPy symbolic computation
-
Mathematical Libraries: NumPy for matrix operations, SymPy for symbolic derivation
-
Control Interface: Joint position controllers with PID tuning
-
Visualization: RViz for 3D visualization, Marker API for end-effector tracking
-
Transform Management: TF2 for coordinate frame transformations
-
Message Types: Custom EndEffector messages for pose commands
-
Controller Manager: ros_control for joint-level control
-
Simulation: Joint state publisher and robot state publisher
-
Build System: CMake, Catkin
-
Version Control: Git
Source Code
-
GitHub Repository: Anthropomorphic Robot Arm Control
-
Documentation: README with implementation details
Video Result
-
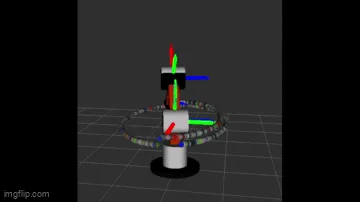
Elliptical Trajectory Demo: Real-time trajectory tracking demonstrating smooth 3D motion control
-
Elliptical Trajectory Demo: Real-time trajectory tracking demonstrating smooth 3D motion control
Process and Development
The project is structured into five critical components: environment setup and reward engineering, DDPG implementation with deterministic policy, SAC implementation with entropy regularization, hyperparameter optimization and ablation studies, and comparative performance analysis between algorithms.
Task 1: Environment Configuration and Reward Shaping
MuJoCo Integration: Configured Humanoid-v5 environment with 376-dimensional observation space including joint angles, velocities, quaternion orientation, and contact forces from feet sensors.
Reward Engineering: Developed multi-component reward function combining survival bonus (+1 per timestep), forward velocity reward (proportional to x-velocity), standing bonus (+2.0 when torso height > 1.0m), and velocity scaling (2x multiplier) to encourage upright forward locomotion.
Action Space Design: Implemented 17-DOF continuous control with torque limits, mapping neural network outputs through tanh activation to ensure valid joint torque ranges preventing motor damage
Task 2: DDPG Algorithm Implementation
Deterministic Policy Network: Created 3-layer Actor network (400-300-17 neurons) with ReLU activations outputting continuous torque values scaled by action bounds for direct motor control.
Critic Q-Network: Implemented state-action value function approximator concatenating 376-dim state and 17-dim action vectors, outputting single Q-value for policy gradient computation.
Ornstein-Uhlenbeck Noise: Developed temporally correlated exploration noise with theta=0.15, initial sigma=0.3 decaying to 0.05, providing smooth action perturbations suitable for continuous control.
Task 3: SAC Algorithm Enhancement
Stochastic Policy: Implemented Gaussian policy outputting mean and log-std for each action dimension, using reparameterization trick for differentiable sampling through policy network.
Automatic Temperature Tuning: Created learnable entropy coefficient (alpha) with target entropy=-17 (negative action dimension), automatically balancing exploration-exploitation without manual tuning.
Twin Q-Networks: Developed dual critic networks taking minimum Q-value to address overestimation bias, improving learning stability in high-dimensional continuous spaces.
Task 4: Training Pipeline and Optimization
Experience Replay Buffer: Implemented circular buffer with 1M capacity storing (state, action, reward, next_state, done) tuples, enabling off-policy learning and sample efficiency.
Soft Target Updates: Applied exponential moving average with tau=0.005 (SAC) and tau=0.001 (DDPG) for target network updates, stabilizing temporal difference learning.
Batch Training Schedule: Configured 256 batch size with learning starting after 1000/5000 steps for SAC/DDPG respectively, performing gradient updates every environment step after warmup.
Task 5: Performance Analysis and Validation
Convergence Metrics: Tracked episode rewards, moving averages, Q-values, and actor losses using TensorBoard, observing SAC convergence at ~20k steps versus DDPG at ~40k steps.
Stability Testing: Evaluated trained policies for continuous walking duration, achieving 8+ hours without falls for SAC while DDPG showed occasional instabilities after 2-3 hours.
Ablation Studies: Tested reward component contributions finding forward velocity bonus critical for gait development, standing bonus essential for stability, and entropy regularization improving exploration efficiency.
Results
The SAC implementation achieves stable bipedal locomotion after approximately 20,000 environment interactions, learning natural walking gaits without any human demonstrations. The agent maintains balance for over 8 hours of continuous walking with average episode rewards exceeding 6000 after convergence. Walking speed reaches 2.5 m/s forward velocity while maintaining upright posture with torso height consistently above 1.0 meters. The learned policy demonstrates robustness to initial conditions, successfully recovering from various starting poses. Comparison with DDPG shows 2x faster learning for SAC with more stable long-term performance. The entropy-regularized SAC policy exhibits more natural motion with smoother joint trajectories compared to the deterministic DDPG policy.
Key Insights
-
Entropy Regularization Advantage: SAC's automatic temperature adjustment eliminates manual tuning while maintaining optimal exploration-exploitation balance throughout training.
-
Reward Shaping Criticality: Standing bonus prevents early convergence to crawling behaviors while forward velocity scaling encourages efficient gaits over simple survival.
-
Exploration Noise Impact: Ornstein-Uhlenbeck noise in DDPG provides smoother exploration than Gaussian noise but still underperforms SAC's principled stochastic policy.
-
Sample Efficiency: Both algorithms require approximately 1M total environment steps for robust policies, with SAC achieving stable gaits 2x faster.
-
Emergent Behaviors: Natural arm swinging and weight shifting emerge without explicit programming, demonstrating the power of end-to-end reinforcement learning
Future Work
-
Curriculum Learning: Implement progressive difficulty increase starting with balance, then stepping, finally continuous walking to accelerate training
-
Domain Randomization: Add variations in mass distribution, joint friction, and ground properties for sim-to-real transfer
-
Hierarchical Control: Develop high-level navigation policy commanding low-level walking controller for goal-directed locomotion
-
Multi-Task Learning: Train single policy for walking, running, turning, and climbing stairs using task-conditioned rewards
-
Model-Based Enhancement: Integrate learned dynamics models for planning and reduced sample complexity
-
Real Robot Deployment: Transfer learned policies to physical humanoid robots using domain adaptation techniques